The Multiphase Dilemma
Commercial reactors contain billions of particles. Tracking them all (Euler-Lagrange) is computationally impossible. Averaging them (Euler-Euler) loses the physics.
Multiscale & Multiphysics Nature
Phenomena spanning 10+ orders of magnitude in time and space
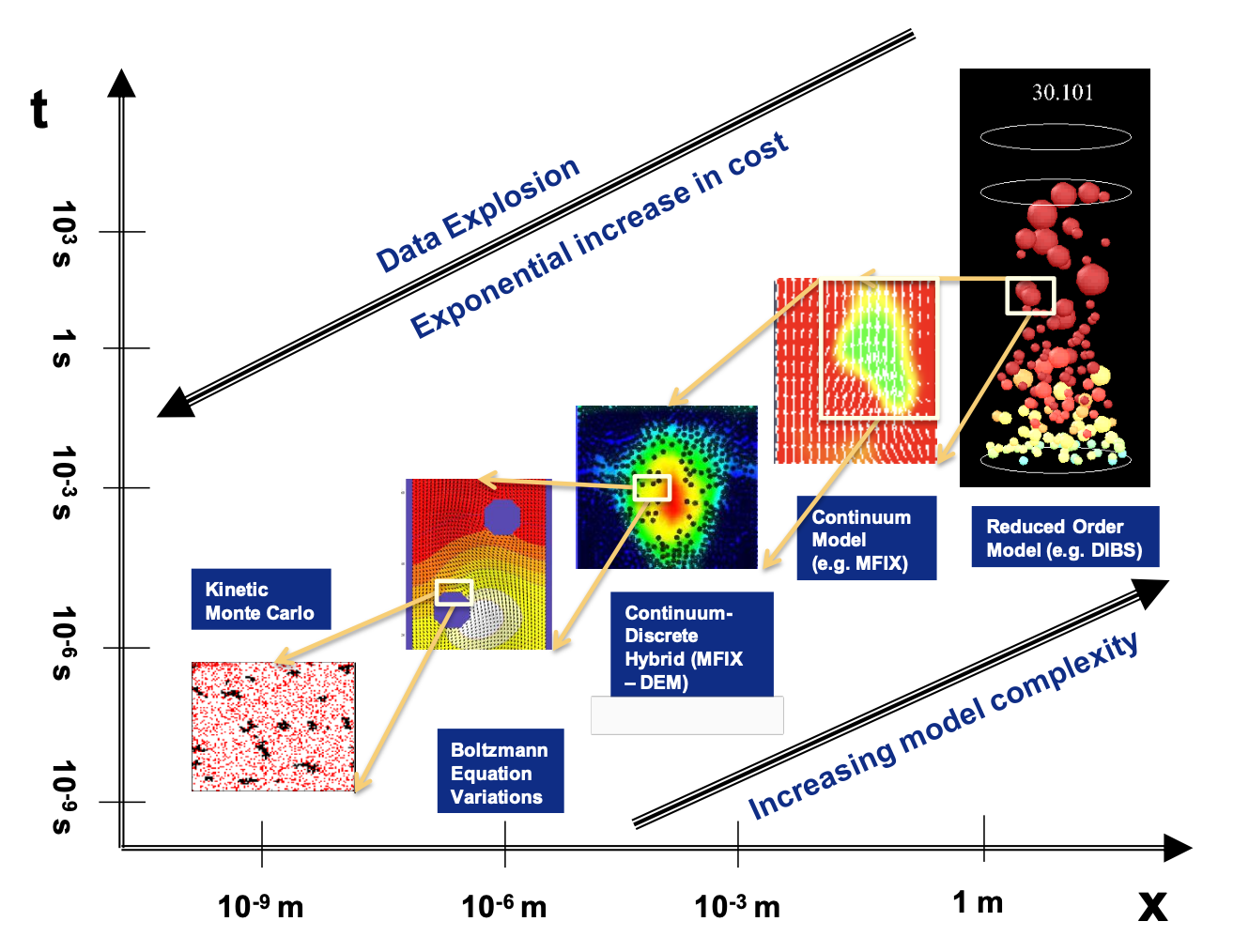
Too Slow (DNS/DEM)
Direct Numerical Simulation tracks every particle and resolves all scales.
Too Vague (TFM)
Two-Fluid Model averages out all structure using empirical closures.
Just Right (DIBS/DHRDM)
Agent-based approach tracks mesoscale structures (bubbles, clusters) directly.
Calibrating DHRDM from Experimental Data
Using NETL riser footage and image analysis to extract cluster statistics
Capture Video
High-speed camera records NETL pilot-scale riser (1m height, 800×588px, 15 fps)
- • Duration: 84 seconds
- • Resolution: 1.7 mm/pixel
- • Sample rate: 1 frame/sec
Image Processing
Adaptive thresholding + morphological operations reveal cluster boundaries
Extract Statistics
Measure cluster properties to calibrate DHRDM parameters
- • Mean width: 6.6 mm
- • Mean height: 91 mm
- • Avg clusters/frame: 84
Raw NETL Video
NETL pilot-scale riser showing particle clusters
Binary Segmentation

Adaptive threshold isolates dense regions
Cluster Labels (DBSCAN)

DBSCAN identifies clusters → calibrates φcrit, ε, minPts
Result: Experimental cluster statistics set realistic targets for simulation parameters